
Die Website häufig zentraler Marketingkanal. Dennoch wissen viele Marketer relativ wenig über die Besucher. Ein Grund, weshalb Unternehmen immer mehr Geld in Webanalyse investieren. Aber wie genau funktioniert Webanalyse überhaupt? Und welche Webanalyse-Tools eignen sich am besten?
Inhaltsverzeichnis
Was ist Webanalyse?
Die Webanalyse (auch Website-Analyse oder Web Analytics genannt) ist eine Marketingdisziplin zur Erfolgsmessung. Betrachtungsgegenstand ist die Art und Weise, wie User mit Webseiten oder mit einer App interagieren. Wissen über das Verhalten von Usern ist Grundvoraussetzung, um das eigene Angebot und die Customer Experience optimieren zu können.
Webanalyse ist ein Teilgebiet der Datenanalyse (“Data Analytics”). Letztere beschäftigt die sich mit Daten jeglicher Art. Zum Beispiel mit dem Fischbestand in der Ostsee.
Warum ist die Webanalyse so wichtig?
Ein Ladenbesitzer erkennt sofort, wenn sich Kunden durch eine Deko angezogen fühlen. Sie sehen deren Blicke und können einen Plausch halten. Als Betreiber einer Website oder eines Online-Shops ist das schwierig. Natürlich lässt sich die Anzahl generierter Anfragen oder der Umsatz erkennen, aber alles davor liegt zunächst mal im Dunkeln:
- Wo kommen die Kunden her?
- Was sind deren Motive und Wünsche?
- Wie oft waren sie bereits auf der Website?
- Auf welche Texte und Bilder sprechen sie gut an?
- Warum verlassen sie die Website wieder, ohne zu kaufen?
Webanalyse hilft dabei, mehr über den User zu erfahren und mit seiner Zielgruppe abzugleichen. Das ist extrem wichtig, um das Angebot und die Werbung optimieren zu können. Sie macht deutlich, wo es hapert, also wo sogenannte “Bottlenecks” versteckt liegen.
Wie funktioniert Website-Analyse?
Normalerweise wird Website-Analyse clientseitig im Browser des Users durchgeführt. Dazu wird dort ein JavaScript gestartet, welches Informationen über das Klick- und Scrollverhalten des Users über verschiedenen Protokolle an einen Analytics Server weiterleitet. Dort werden die Daten gesammelt, bereinigt, anonymisiert, aggregiert und in Informationen umgewandelt (z. B. Charts und Diagramme).
Was ist Tracking?
Tracking funktioniert im Prinzip genauso. Hier werden die generierten Daten jedoch nicht anonymisiert, sondern allenfalls pseudonymisiert. Durch die individuelle Identifizierung beim Tracking lassen sich Persönlichkeitsprofile und Verhaltensmuster bilden. Das Ziel ist es, für jene User ein Profil zu erstellen, um z. B. zielgerichtetere Werbung aussteuern zu können.
Tools zur Webanalyse
Bei der Analyse von Webseiten und Shops helfen spezielle Tools, die im Großen und Ganzen ähnlich aufgebaut sind. Zu den bekanntesten Website-Analyse-Tools gehören:
- Piwik Pro
- Google Analytics (GA4)
- Plausible
- matomo
- Adobe Analytics
- eTracker
Rechtliche Einschränkungen
Eine große Herausforderung resultiert aus den gesetzlichen Vorgaben zum Datenschutzgesetz; insbesobdere aus der DSGVO. Im Kern steht die Herausforderung, wiederkehrende User zu identifizieren. Das ist wichtig, um aussagekräftige Besucherzahlen berechnen zu können.
Üblicherweise wird dazu auf dem Endgerät des Users automatisch ein Cookie gespeichert. Es gibt jedoch auch auch viele andere Methoden, wie zum Beispiel der Zugriff auf den sogenannten Local Storage.
Das Problem aus Sicht des Datenschutzes ist, dass auf diese Weise generierte Daten einen Personenbezug bekommen. Denn mit mehr oder weniger Aufwand lassen sich die Trackingdaten einem Individuum zuordnen.
Mittlerweile gibt einige Ansätze, die ein datenschutzkonsformes Tracking versprechen. Tatsächlich ist dies jedoch rein vom Prinzip her nie zu 100 % möglich.
Device Fingerprint Tracking
Analytics Tools wie Matomo setzen auf sogenannte Fingerprints, um wiederkehrende Besucher zu identifizieren. Dazu werden digitale Spuren der User wie z. B. IP- und MAC-Adresse, Betriebssystem, Browsertyp und -version, Plug-ins, installierte Schriften und weitere spezielle Einstellungen gespeichert.
Technische Einschränkungen
Webanalyse funktioniert nur so weit, wie es Webbrowser zulassen. Und die sind vermehrt restriktiv. Insbesondere, wenn es um die Ausführung von Trackingskripten und die Speicherung von Cookies geht. Das gilt vor allem für Safari. Hier ist seit einiger Zeit das sogenannte Intelligent Tracking Prevention (ITP) für Millionen von Apple-Usern standardmäßig aktiviert. Aber auch Microsoft Edge und Google Chrome setzen verstärkt auf Tracking Prevention. Dazu werden auch Fingerprints gezielt verfälscht.
Allgemeine Kennzahlen
- Eindeutige Sitzungen (Sessions)
- Eindeutige Besucher (Visitors) einer Seite
- Seitenaufrufe (Page Views)
Kennzahlen zu Seiten
Analyse-Tools präsentieren Performancedaten zu allen Seiten. Dazu gehören:
- Seitenaufrufe (Page Views)
- Verweildauer
- Absprünge (Bounce)
- Ausstiege
Daten zu Sitzungen
Gängige Web Analytics Tools liefern einige Informationen zum User:
- Wiederkehrer (Verknüpfung mit vergangenen Sitzungen)
- Verwendeter Client und Betriebssystem
- Display- und Bildschirmauflösung
- Region / Herkunft
- Suchbegriff (bei Onpage-Suche)
- Suchbegriff (bei generischer Suche)
- Besuchte Seiten
Events in GA4
In modernen Analyse-Tools dreht sich alles um Events (Ereignissen). In Google Analytics (GA4) werden einige sogar automatisch erfasst (siehe Liste). Andere müssen erst einmal manuell eingerichtet werden, wozu jedoch nur wenige Klicks notwendig sind.
page_view: Dies ist das Seitenaufruf-Event, welches bei jedem Pagereload gefeuert wird.
session_start: Dieses Event wird mit dem ersten page_view gefeuert. Im Anschluss werden für 30 Minuten alle Events der Sitzung zugeordnet.
user_engagement: Das Ereignis wird beim Verlassen einer Seite gesendet. Es enthält Informationen zum Status der Sitzungsinteraktion und zur Dauer des Nutzer-Engagements. Es wird nicht gesendet, wenn weniger als eine Sekunde vor dem geplanten Zeitpunkt bereits ein Ereignis übergeben wurde.
first_visit: Der User besucht zum ersten Mal die Website.
Zu jedem Event werden weitere Daten bereitgestellt. Zum Beispiel die ID des Users, Informationen zum Client, Herkunft bzw. Referrer und so weiter.
Webanalyse vs. Klickpfad-Analyse
Klickpfad-Analysen sind ein wichtiger Baustein in der Webanalyse. Quasi alle gängigen Tools liefern entsprechende Features. Das Ziel einer Klickpfad-Analyse ist es, Schwachstellen auf der Website zu identifizieren. Dazu werden Segmente von Usern gebildet und geprüft, wo die Abbruch- und Ausstiegsrate auffallig groß ist.
Mehr zum Thema findest Du in diesem Artikel: Warum Du den Klickpfad Deiner Kunden kennen solltest.
Serverseitiges Tracking
Ebenfalls eine Daseinsberechtigung hat severseitiges Tracking (nicht zu verwechseln mit serverseitigem Tagging). Anders als bei konventioneller Webanalyse erfolgt hier die Tracking auf einem Server.
Das bringt einige Vorteile mit sich. So funktioniert serverseitiges Tracking deutlich zuverlässiger, weil Cookie Consent und Tracking Prevention keine Rolle mehr spielen.
Nachteile: Viele Interaktionen des Users lassen sich nicht tracken, wie z. B. das Scrollen auf einer Seite.
Qualitative Webanalyse
Neben der quantitativen Webanalyse auf Basis getrackter Daten gibt es auch qualitative Methoden aus dem Bereich Customer Research. Sie basieren auf das Feedback “echter” User und sind deshalb mit etwas mehr Aufwand verbunden. Sie liefern jedoch Informationen, an die man mit datengetriebener Webanalyse kaum gelangen kann:
- Screen Recordings
- Interviews
- Umfragen
- Cognitive Walkthrough
Nutzung von Segmenten
Moderne Website-Analyse-Tools sind kinderleicht zu bedienen. Das ist Fluch und Segen zugleich, denn die präsentierten Daten und Charts verleiten zu falschen Schlussfolgerungen.
Um Schlussfolgerungen ziehen zu können, sollten die generierten Daten von möglichst gleichartigen Usern stammen. Also zum Beispiel Bestandskunde. Deshalb steht und fällt erfolgreiche Webanalyse mit dem Bilden von Segmenten. Das wiederum ist schwierig, wenn die Datenmenge zu gering ist.
Segmente sind gefilterte Trafficdaten. Sie lassen sich mit so ziemlich jedem gängigen Tracking-Tool anlegen. Die Filterung erfolgt zum Beispiel nach Herkunft der Traffics oder nach Events.
Verzerrtes Bild der Realität
Eine weitere Hürde: Die von Website-Analyse-Tools gelieferten Daten sind normalerweise aggregiert. Auch bilden sie nicht das Gesamtbild ab, weil durch fehlendes Cookie Consent und Tracking Prevention viele Daten fehlen. Deshalb liefern die Tools oft ein verzerrtes Bild der Realität. Es ist deshalb ratsam, mehr als nur eine einzige Datenquelle anzuzapfen.
Alternative zu umfassender Webanalyse
Einige Analytics Tools beschränken sich auf wesentliche Kennzahlen und verzichten umgekehrt auf Cookies und Fingerprinting. So trackt, sammelt und speichert zum Beispiel Plausible keine personenbezogenen Daten oder persönlich identifizierbaren Informationen. Nachteil: wiederkehrende User könne nicht identifiziert werden. Ebenso ist ein Tracking über mehrere Geräte hinweg nicht möglich.
Dashboards und Berichte
Um relevante Daten in Echtzeit griffbereit zu haben, benötigst Du ein auf Deine Aufgabe ausgerichtetes Dashboard. Auch automatisierte Berichte können die Arbeit erleichtern. Professionelle Dashboards kannst Du in Sekundenschnelle u. a. mit dem Google Data Studio erstellen.
Deshalb sind wir auf einem Auge blind.
Stell Dir vor, in einer Bar verschüttet der Kellner die Hälfte Deiner Margarita und füllt sie mit Wasser wieder auf. Wie schmeckt Dir das wohl?
Ähnlich ist es bei Website-Analytics: Relevante Daten gehen zuhauf verloren. Im Gegenzug kommen unbrauchbare Daten ins Spiel. Das Resultat ist ein Gemisch, welches die Realität nur bedingt widerspiegelt. Fehlentscheidungen sind so vorprogrammiert.
Daten sind nicht gleich Daten.
Daten helfen uns dabei, bessere Entscheidungen zu treffen und besser mit Zielkunden zu kommunizieren. Deshalb gehören sie zum wichtigsten Treibstoff für Unternehmen der Zukunft. Nicht umsonst sagen einige, Daten seien das neue Öl.
Ähnlich wie Rohöl gibt es auch bei den Daten qualitative Unterschiede. Die wichtigsten Qualitätsfaktoren sind:
- Richtigkeit: Sind ausgegebene Werte korrekt?
- Gültigkeit: Sind ausgegebene Werte noch gültig?
- Vollständigkeit: Fehlen Datensätze und Werte?
- Aktualität: Sind ausgegebene Werte aktuell?
- Relevanz: Sind die Daten für den Einsatzzweck relevant?
- Konsistenz: Sind die Daten frei von Widersprüchen?

Was ist an unzulänglichen Rohdaten so gefährlich?
Schwefelhaltiges Rohöl kann man noch zurechtbiegen. Bei Daten ist es schon schwieriger: Fehler oder fehlende Daten erkennt man nicht mit bloßem Auge. Schon gar nicht, nachdem sie von Google und Co. aggregiert worden sind. Es entsteht ein verzerrtes Abbild der Realität.
Problem 1: Unvollständige Daten
Daten für Website Analytics sind vor allem eines: unvollständig. In manchen Fällen werden rund 80 % der Besucher gar nicht erfasst oder wenigstens nicht wiedererkannt. Fehlende Daten sind bei der Erfolgsmessung alles andere als hilfreich. Darüber hinaus dauert es länger, bis eine Erhebung statistisch signifikant ist, d.h die Irrtumswahrscheinlichkeit einer These sich in Grenzen hält.
Fehlendes Cookie Consent
Hast Du mal getestet, wie viele Besucher beim Aufpoppen des Cookie Banners ihr Ok verweigern? Im Netz geistern Zustimmungsraten von 10 bis 90 % – also in einer enormen Spannbreite. Große Unterschiede gibt es abhängig von der Branche, der Marken-Vertrauenswürdigkeit und der Aufmachung des Cookie Banners. Dazu muss man sagen, dass die wenigsten Banner den gesetzlichen Anforderungen genügen.
Tracking Prevention
Wiederkehrende Besucher werden normalerweise per Cookie oder per Eintrag in dem sogenannten Local Storage identifiziert. Doch diese Daten sind oft nach ein paar Wochen wieder weg. Entweder, Tracking Prevention Tools das Ablaufdatum verkürzen. Oder aber weil User ihren Cache etc. regelmäßig löschen. Ad Blocker Tools blockieren Cookies oft vollständig.
Verfallszeit von Cookies
Wiederkehrende Besucher werden normalerweise per Cookie oder per Eintrag in dem sogenannten Local Storage identifiziert. Doch diese Daten sind oft nach ein paar Wochen wieder weg. Entweder, Tracking Prevention Tools das Ablaufdatum verkürzen. Oder aber weil User ihren Cache etc. regelmäßig löschen. Ad Blocker Tools blockieren Cookies oft vollständig.
Technische Probleme
Ebenfalls nicht zu unterschätzen ist der Einfluss technischer Probleme. Viele Browser-Sessions erzeugen keinen sauberen Datenstrom, weil sich Skripte gegenseitig blockieren oder verhaken. Besonders dann, wenn mehrere Tags parallel aufgerufen werden. Auch Cookie Consent Tools sind nicht selten dafür verantwortlich, dass Tracking Streams irrtümlich unterbrochen werden.
Sonstige Hürden
Besonders schwierig ist das Tracken von Usern, die im Wechsel verschiedene Endgeräte nutzen. Das Chaos ist perfekt, wenn das sich das eigene Webangebot über verschiedene Domains verteilt. Der Grund: First-party Cookies beziehen sich stets auf eine konkrete Domain bzw. Subdomain.
Problem 2: Irrelevante Daten
Besonders fies sind irrelevante Daten, denn sie lenken den Web Analyst auf eine falsche Fährte. Nicht zuletzt, weil sie oft für statische Ausreißer verantwortlich sind. Das führt dazu, dass zuhauf irreführende Durchschnittswerte berechnet werden.
In der Webanalyse gibt man sich größte Mühe, die Klicks der Buyer Personas zu isolieren. In Zeiten von Homeoffice ist das naturgemäß schwierig. Die wenigsten IP-Nummern lassen sich eindeutig einer Organisation zuordnen. Ein noch größeres Problem sind jedoch Bots …
Bot-Traffic
Es wird angenommen, dass über 40 % des gesamten Internet-Traffics aus Bot-Traffic besteht, und ein beträchtlicher Teil davon sind böswillige Bots. Diese stellen nicht nur ein Sicherheitsrisiko dar, sondern verfälschen auch massiv die Website Analytics.
Das Fiese ist, dass Bots nicht so leicht von echten Besuchern zu unterscheiden sind. Google und Co. gleichen deshalb die IP-Nummern mit Datenbanken ab, in denen Bot-Netzwerke verzeichnet sind. Das klappt jedoch nicht immer perfekt.
Das Problem wird jedoch größer: Bots der neuesten Generation verhalten sich wie Menschen. Dazu imitieren sie sogar Cursor- und Scroll-Bewegungen. Mehr noch: Sie ändern ständig ihre IP-Adresse, ihren User Agent und löschen ihre Cookies.

Höhere Datenqualität mit Google Analytics?
Jein! Fehlende Daten und Cookies kann natürlich Google auch nicht mehr herzaubern. Darüber hinaus werden beim Aggregieren der Daten die Auswertungen leicht verfälscht. Vor allem durch das eingesetzte Data Sampling.
Neuartige Features wie der Consent Mode von versprechen Hilfe – doch hier bleiben u. a. Fragen zum Datenschutz unbeantwortet.
Ach ja, was Google gut kann, ist das Herausfiltern von Bot-Zugriffen.
Lösungsansätze
Login-Bereich
Es gibt unzählige Ansätze, die Datengenerierung im Rahmen der Web Analytics zu optimieren. Ganz vorne steht die Implementierung eines Login-Bereichs für Websitebesucher (Closed User Group).
Im Rahmen eines Login-Bereichs ist Tracking naturgemäß deutlich einfacher und zuverlässiger. Auch kann ein rechtssicheres Opt-in vorausgesetzt werden. Viele Shops nutzen längst Log-ins, aber aus Komfortgründen wollen/sollen sie natürlich auch anonym zugänglich sein.
Serverseitiges Tag Management
Hilfreich ist es, wenn die Tags für GA, Facebook und Co nicht länger innerhalb des Browsers ausgeführt werden. Das ermöglicht serverseitiges Tag Management. Hier liegen die entsprechenden Skript auf dem Server und nutzen APIs zur Kommunikation.
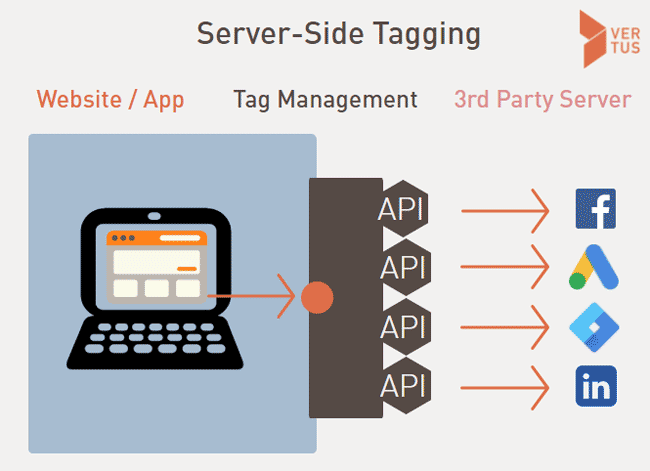
Serverseitiges Tagging ist jedoch kein Allheilmittel. Zumal ohne Cookie Consent auch hier nichts geht.
Web Analytics überprüfen
Händisches überprüfen war gestern. Pfiffige Tools helfen dabei, Fehler im Analytics Setup in Sekundenschnelle zu identifizieren. Hier ein paar ausgewählte Tools im Überblick:
- GA Diagnostics Notification Tool: Liefert automatisch Warnungen und kann über das Benachrichtigungen-Icon idirekt aus der GA-Benutzeroberfläche aufgerufen werden.
- Fiddler: Auf Client installierbarer Proxy Server zum Debuggen von GA Requests. Sehr praktisch.
- Screaming Frog SEO Spider: Beliebtes Tool zur Analyse der eigenen Website.
- Google Trouble Shooter Tool: Ebenfalls hilfreich ist das interaktive Trouble Shooter Tool von Google. Für UA ist es hier verfügbar. Für GA4 ist es hier verfügbar.
- Google Analytics Debugger als Chrome Plugin.
- Diverste fest integrierte Tools im Chrome Browser (z. B. Google Developer Console)
- GA Checker: Tool zum Überprüfen einer ganzen Website (bis zu 10.000 Seiten) im Hinblick auf alle gängigen Google Tags. Mehr erfahren.
Natürlich sind solche Analysen kein Lösungsansatz. Aber sie sind ein erster Schritt.
Sonstige Maßnahmen
Du kannst auch erst mal auf spezifischere Maßnahmen zurückgreifen wie Consent Retrieval per A/B-Test, Bot-Filterungen mit GTM-Spamschutz, Session Stitching auf Hit-Level oder dem Vergleich des Verhaltens eingeloggter User (uid-Parameter) und Pseudo-Besuchern (cid-Parameter).
Komplett auf Web Analytics verzichten?
Viele Marketer kommen zu dem Schluss, dass ihnen Web Analytics eher schadet als nützt. Insbesondere dann, wenn sie die generierten Daten eh nie benutzt. Eine Lösung kann aussehen, auf sämtliche Webanalyse-Tools zu verzichten. Das erhöht die Geschwindigkeit der Website und ermöglicht ggf. den Verzicht eines Cookie Consent Banners. Gute Insights liefern dann die Kontakt- und Bestellformulare sowie, wenn auch zeitverzögert, die Google Search Console.
Fazit
Webanalyse ist wichtig, um ein Angebot besser auf Kunden ausrichten zu können. Zum Glück gibt es sehr leistungsstarke Tools. Ohne ein Minimum an Zahlenverständnis drohen jedoch falsche Schlussfolgerungen. Es lohnt sich im Zweifel, erfahrene Data Analysts mit ins Boot zu holen. Und perspektivisch Rohdaten unabhängig von Google und Co. zu generieren.
Ergänzende Artikel

Moin aus Hamburg! Mein Name ist Frank und ich beschäftige mich seit über 25 Jahren intensiv mit digitalem Marketi8ng.
Du möchtest dich und dein Marketing weiterentwickeln? Dann lass uns sprechen!